# Storm 编程模型
## 一、简介
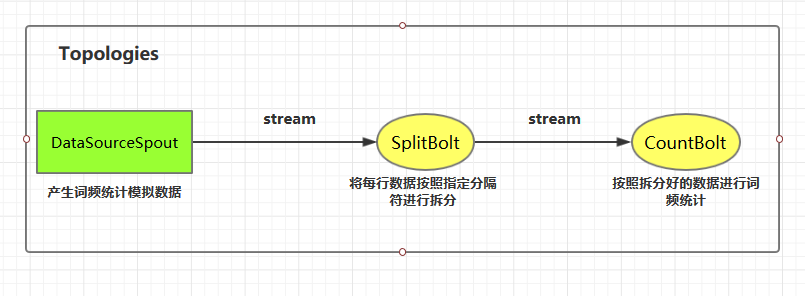
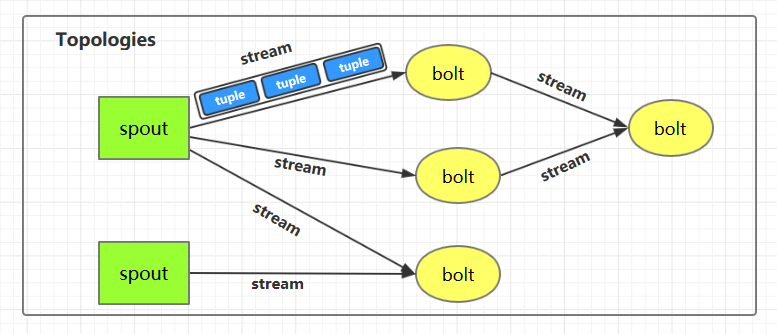
下图为 Strom 的运行流程图,在开发 Storm 流处理程序时,我们需要采用内置或自定义实现 `spout`(数据源) 和 `bolt`(处理单元),并通过 `TopologyBuilder` 将它们之间进行关联,形成 `Topology`。
## 二、IComponent接口
`IComponent` 接口定义了 Topology 中所有组件 (spout/bolt) 的公共方法,自定义的 spout 或 bolt 必须直接或间接实现这个接口。
```java
public interface IComponent extends Serializable {
/**
* 声明此拓扑的所有流的输出模式。
* @param declarer 这用于声明输出流 id,输出字段以及每个输出流是否是直接流(direct stream)
*/
void declareOutputFields(OutputFieldsDeclarer declarer);
/**
* 声明此组件的配置。
*
*/
Map getComponentConfiguration();
}
```
## 三、Spout
### 3.1 ISpout接口
自定义的 spout 需要实现 `ISpout` 接口,它定义了 spout 的所有可用方法:
```java
public interface ISpout extends Serializable {
/**
* 组件初始化时候被调用
*
* @param conf ISpout 的配置
* @param context 应用上下文,可以通过其获取任务 ID 和组件 ID,输入和输出信息等。
* @param collector 用来发送 spout 中的 tuples,它是线程安全的,建议保存为此 spout 对象的实例变量
*/
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
/**
* ISpout 将要被关闭的时候调用。但是其不一定会被执行,如果在集群环境中通过 kill -9 杀死进程时其就无法被执行。
*/
void close();
/**
* 当 ISpout 从停用状态激活时被调用
*/
void activate();
/**
* 当 ISpout 停用时候被调用
*/
void deactivate();
/**
* 这是一个核心方法,主要通过在此方法中调用 collector 将 tuples 发送给下一个接收器,这个方法必须是非阻塞的。
* nextTuple/ack/fail/是在同一个线程中执行的,所以不用考虑线程安全方面。当没有 tuples 发出时应该让
* nextTuple 休眠 (sleep) 一下,以免浪费 CPU。
*/
void nextTuple();
/**
* 通过 msgId 进行 tuples 处理成功的确认,被确认后的 tuples 不会再次被发送
*/
void ack(Object msgId);
/**
* 通过 msgId 进行 tuples 处理失败的确认,被确认后的 tuples 会再次被发送进行处理
*/
void fail(Object msgId);
}
```
### 3.2 BaseRichSpout抽象类
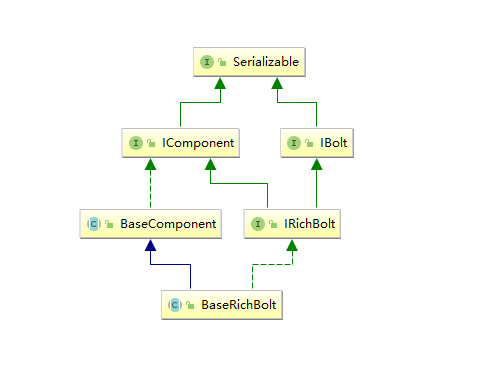
**通常情况下,我们实现自定义的 Spout 时不会直接去实现 `ISpout` 接口,而是继承 `BaseRichSpout`。**`BaseRichSpout` 继承自 `BaseCompont`,同时实现了 `IRichSpout` 接口。
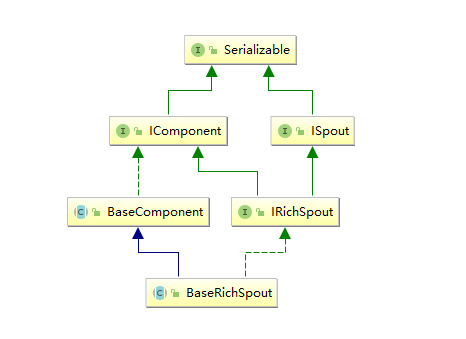
`IRichSpout` 接口继承自 `ISpout` 和 `IComponent`,自身并没有定义任何方法:
```java
public interface IRichSpout extends ISpout, IComponent {
}
```
`BaseComponent` 抽象类空实现了 `IComponent` 中 `getComponentConfiguration` 方法:
```java
public abstract class BaseComponent implements IComponent {
@Override
public Map getComponentConfiguration() {
return null;
}
}
```
`BaseRichSpout` 继承自 `BaseCompont` 类并实现了 `IRichSpout` 接口,并且空实现了其中部分方法:
```java
public abstract class BaseRichSpout extends BaseComponent implements IRichSpout {
@Override
public void close() {}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
}
```
通过这样的设计,我们在继承 `BaseRichSpout` 实现自定义 spout 时,就只有三个方法必须实现:
+ **open** : 来源于 ISpout,可以通过此方法获取用来发送 tuples 的 `SpoutOutputCollector`;
+ **nextTuple** :来源于 ISpout,必须在此方法内部发送 tuples;
+ **declareOutputFields** :来源于 IComponent,声明发送的 tuples 的名称,这样下一个组件才能知道如何接受。
## 四、Bolt
bolt 接口的设计与 spout 的类似:
### 4.1 IBolt 接口
```java
/**
* 在客户端计算机上创建的 IBolt 对象。会被被序列化到 topology 中(使用 Java 序列化),并提交给集群的主机(Nimbus)。
* Nimbus 启动 workers 反序列化对象,调用 prepare,然后开始处理 tuples。
*/
public interface IBolt extends Serializable {
/**
* 组件初始化时候被调用
*
* @param conf storm 中定义的此 bolt 的配置
* @param context 应用上下文,可以通过其获取任务 ID 和组件 ID,输入和输出信息等。
* @param collector 用来发送 spout 中的 tuples,它是线程安全的,建议保存为此 spout 对象的实例变量
*/
void prepare(Map stormConf, TopologyContext context, OutputCollector collector);
/**
* 处理单个 tuple 输入。
*
* @param Tuple 对象包含关于它的元数据(如来自哪个组件/流/任务)
*/
void execute(Tuple input);
/**
* IBolt 将要被关闭的时候调用。但是其不一定会被执行,如果在集群环境中通过 kill -9 杀死进程时其就无法被执行。
*/
void cleanup();
```
### 4.2 BaseRichBolt抽象类
同样的,在实现自定义 bolt 时,通常是继承 `BaseRichBolt` 抽象类来实现。`BaseRichBolt` 继承自 `BaseComponent` 抽象类并实现了 `IRichBolt` 接口。
`IRichBolt` 接口继承自 `IBolt` 和 `IComponent`,自身并没有定义任何方法:
```
public interface IRichBolt extends IBolt, IComponent {
}
```
通过这样的设计,在继承 `BaseRichBolt` 实现自定义 bolt 时,就只需要实现三个必须的方法:
- **prepare**: 来源于 IBolt,可以通过此方法获取用来发送 tuples 的 `OutputCollector`;
- **execute**:来源于 IBolt,处理 tuples 和发送处理完成的 tuples;
- **declareOutputFields** :来源于 IComponent,声明发送的 tuples 的名称,这样下一个组件才能知道如何接收。
## 五、词频统计案例
### 5.1 案例简介
这里我们使用自定义的 `DataSourceSpout` 产生词频数据,然后使用自定义的 `SplitBolt` 和 `CountBolt` 来进行词频统计。
> 案例源码下载地址:[storm-word-count](https://github.com/heibaiying/BigData-Notes/tree/master/code/Storm/storm-word-count)
### 5.2 代码实现
#### 1. 项目依赖
```xml
org.apache.storm
storm-core
1.2.2
```
#### 2. DataSourceSpout
```java
public class DataSourceSpout extends BaseRichSpout {
private List list = Arrays.asList("Spark", "Hadoop", "HBase", "Storm", "Flink", "Hive");
private SpoutOutputCollector spoutOutputCollector;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.spoutOutputCollector = spoutOutputCollector;
}
@Override
public void nextTuple() {
// 模拟产生数据
String lineData = productData();
spoutOutputCollector.emit(new Values(lineData));
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("line"));
}
/**
* 模拟数据
*/
private String productData() {
Collections.shuffle(list);
Random random = new Random();
int endIndex = random.nextInt(list.size()) % (list.size()) + 1;
return StringUtils.join(list.toArray(), "\t", 0, endIndex);
}
}
```
上面类使用 `productData` 方法来产生模拟数据,产生数据的格式如下:
```properties
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm
```
#### 3. SplitBolt
```java
public class SplitBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
@Override
public void execute(Tuple input) {
String line = input.getStringByField("line");
String[] words = line.split("\t");
for (String word : words) {
collector.emit(new Values(word));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
```
#### 4. CountBolt
```java
public class CountBolt extends BaseRichBolt {
private Map counts = new HashMap<>();
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Integer count = counts.get(word);
if (count == null) {
count = 0;
}
count++;
counts.put(word, count);
// 输出
System.out.print("当前实时统计结果:");
counts.forEach((key, value) -> System.out.print(key + ":" + value + "; "));
System.out.println();
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
```
#### 5. LocalWordCountApp
通过 TopologyBuilder 将上面定义好的组件进行串联形成 Topology,并提交到本地集群(LocalCluster)运行。通常在开发中,可先用本地模式进行测试,测试完成后再提交到服务器集群运行。
```java
public class LocalWordCountApp {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout());
// 指明将 DataSourceSpout 的数据发送到 SplitBolt 中处理
builder.setBolt("SplitBolt", new SplitBolt()).shuffleGrouping("DataSourceSpout");
// 指明将 SplitBolt 的数据发送到 CountBolt 中 处理
builder.setBolt("CountBolt", new CountBolt()).shuffleGrouping("SplitBolt");
// 创建本地集群用于测试 这种模式不需要本机安装 storm,直接运行该 Main 方法即可
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalWordCountApp",
new Config(), builder.createTopology());
}
}
```
#### 6. 运行结果
启动 `WordCountApp` 的 main 方法即可运行,采用本地模式 Storm 会自动在本地搭建一个集群,所以启动的过程会稍慢一点,启动成功后即可看到输出日志。
## 六、提交到服务器集群运行
### 6.1 代码更改
提交到服务器的代码和本地代码略有不同,提交到服务器集群时需要使用 `StormSubmitter` 进行提交。主要代码如下:
> 为了结构清晰,这里新建 ClusterWordCountApp 类来演示集群模式的提交。实际开发中可以将两种模式的代码写在同一个类中,通过外部传参来决定启动何种模式。
```java
public class ClusterWordCountApp {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout());
// 指明将 DataSourceSpout 的数据发送到 SplitBolt 中处理
builder.setBolt("SplitBolt", new SplitBolt()).shuffleGrouping("DataSourceSpout");
// 指明将 SplitBolt 的数据发送到 CountBolt 中 处理
builder.setBolt("CountBolt", new CountBolt()).shuffleGrouping("SplitBolt");
// 使用 StormSubmitter 提交 Topology 到服务器集群
try {
StormSubmitter.submitTopology("ClusterWordCountApp", new Config(), builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {
e.printStackTrace();
}
}
}
```
### 6.2 打包上传
打包后上传到服务器任意位置,这里我打包后的名称为 `storm-word-count-1.0.jar`
```shell
# mvn clean package -Dmaven.test.skip=true
```
### 6.3 提交Topology
使用以下命令提交 Topology 到集群:
```shell
# 命令格式: storm jar jar包位置 主类的全路径 ...可选传参
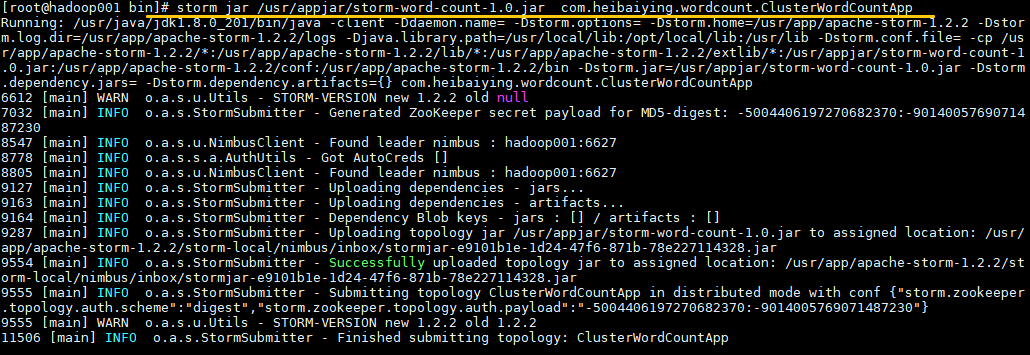
storm jar /usr/appjar/storm-word-count-1.0.jar com.heibaiying.wordcount.ClusterWordCountApp
```
出现 `successfully` 则代表提交成功:
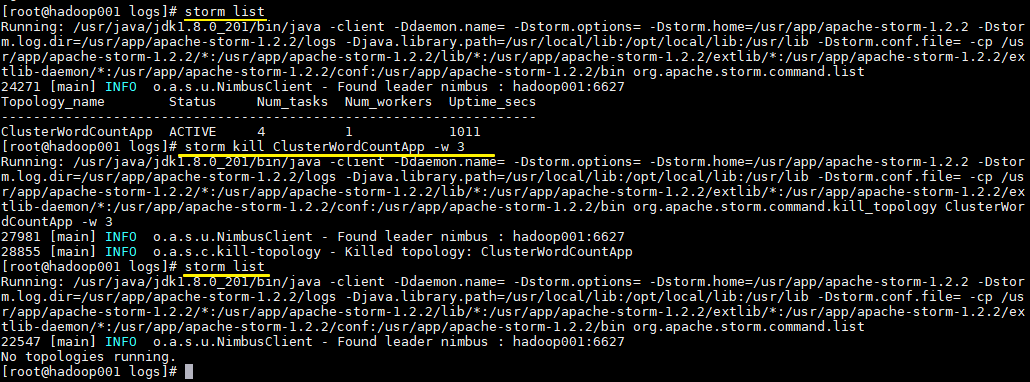
### 6.4 查看Topology与停止Topology(命令行方式)
```shell
# 查看所有Topology
storm list
# 停止 storm kill topology-name [-w wait-time-secs]
storm kill ClusterWordCountApp -w 3
```
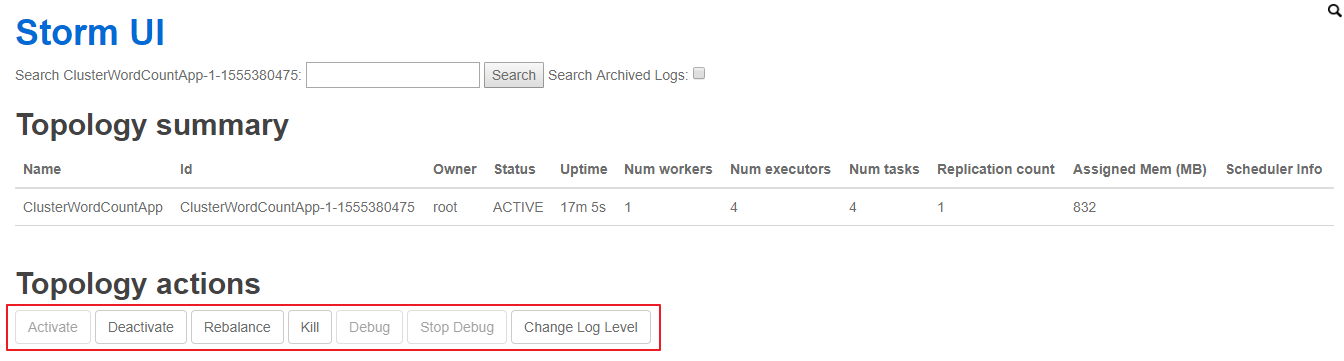
### 6.5 查看Topology与停止Topology(界面方式)
使用 UI 界面同样也可进行停止操作,进入 WEB UI 界面(8080 端口),在 `Topology Summary` 中点击对应 Topology 即可进入详情页面进行操作。
## 七、关于项目打包的扩展说明
### mvn package的局限性
在上面的步骤中,我们没有在 POM 中配置任何插件,就直接使用 `mvn package` 进行项目打包,这对于没有使用外部依赖包的项目是可行的。但如果项目中使用了第三方 JAR 包,就会出现问题,因为 `package` 打包后的 JAR 中是不含有依赖包的,如果此时你提交到服务器上运行,就会出现找不到第三方依赖的异常。
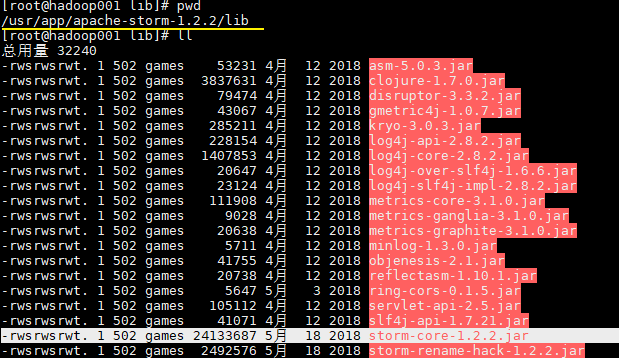
这时候可能大家会有疑惑,在我们的项目中不是使用了 `storm-core` 这个依赖吗?其实上面之所以我们能运行成功,是因为在 Storm 的集群环境中提供了这个 JAR 包,在安装目录的 lib 目录下:
为了说明这个问题我在 Maven 中引入了一个第三方的 JAR 包,并修改产生数据的方法:
```xml
org.apache.commons
commons-lang3
3.8.1
```
`StringUtils.join()` 这个方法在 `commons.lang3` 和 `storm-core` 中都有,原来的代码无需任何更改,只需要在 `import` 时指明使用 `commons.lang3`。
```java
import org.apache.commons.lang3.StringUtils;
private String productData() {
Collections.shuffle(list);
Random random = new Random();
int endIndex = random.nextInt(list.size()) % (list.size()) + 1;
return StringUtils.join(list.toArray(), "\t", 0, endIndex);
}
```
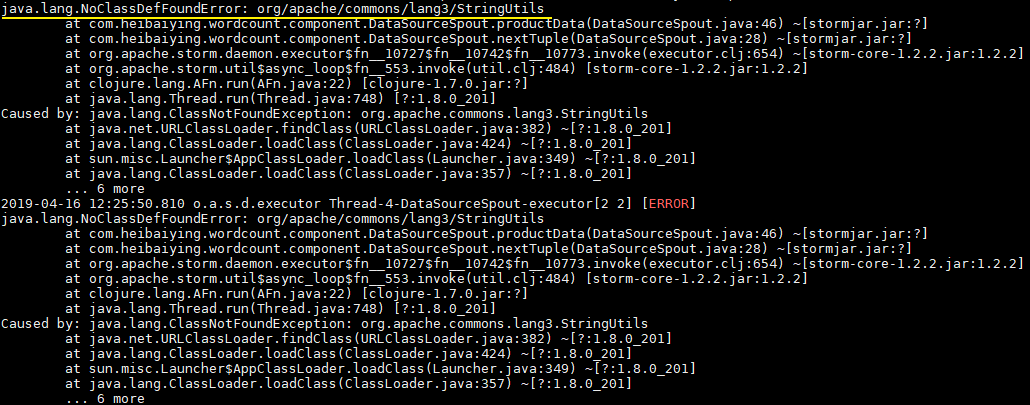
此时直接使用 `mvn clean package` 打包运行,就会抛出下图的异常。因此这种直接打包的方式并不适用于实际的开发,因为实际开发中通常都是需要第三方的 JAR 包。
想把依赖包一并打入最后的 JAR 中,maven 提供了两个插件来实现,分别是 `maven-assembly-plugin` 和 `maven-shade-plugin`。鉴于本篇文章篇幅已经比较长,且关于 Storm 打包还有很多需要说明的地方,所以关于 Storm 的打包方式单独整理至下一篇文章:
[Storm 三种打包方式对比分析](https://github.com/heibaiying/BigData-Notes/blob/master/notes/Storm三种打包方式对比分析.md)
## 参考资料
1. [Running Topologies on a Production Cluster](http://storm.apache.org/releases/2.0.0-SNAPSHOT/Running-topologies-on-a-production-cluster.html)
2. [Pre-defined Descriptor Files](http://maven.apache.org/plugins/maven-assembly-plugin/descriptor-refs.html)