# Spark SQL 外部数据源
## 一、简介
### 1.1 多数据源支持
Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景。
- CSV
- JSON
- Parquet
- ORC
- JDBC/ODBC connections
- Plain-text files
> 注:以下所有测试文件均可从本仓库的[resources](https://github.com/heibaiying/BigData-Notes/tree/master/resources) 目录进行下载
### 1.2 读数据格式
所有读取 API 遵循以下调用格式:
```scala
// 格式
DataFrameReader.format(...).option("key", "value").schema(...).load()
// 示例
spark.read.format("csv")
.option("mode", "FAILFAST") // 读取模式
.option("inferSchema", "true") // 是否自动推断 schema
.option("path", "path/to/file(s)") // 文件路径
.schema(someSchema) // 使用预定义的 schema
.load()
```
读取模式有以下三种可选项:
| 读模式 | 描述 |
| --------------- | ------------------------------------------------------------ |
| `permissive` | 当遇到损坏的记录时,将其所有字段设置为 null,并将所有损坏的记录放在名为 _corruption t_record 的字符串列中 |
| `dropMalformed` | 删除格式不正确的行 |
| `failFast` | 遇到格式不正确的数据时立即失败 |
### 1.3 写数据格式
```scala
// 格式
DataFrameWriter.format(...).option(...).partitionBy(...).bucketBy(...).sortBy(...).save()
//示例
dataframe.write.format("csv")
.option("mode", "OVERWRITE") //写模式
.option("dateFormat", "yyyy-MM-dd") //日期格式
.option("path", "path/to/file(s)")
.save()
```
写数据模式有以下四种可选项:
| Scala/Java | 描述 |
| :----------------------- | :----------------------------------------------------------- |
| `SaveMode.ErrorIfExists` | 如果给定的路径已经存在文件,则抛出异常,这是写数据默认的模式 |
| `SaveMode.Append` | 数据以追加的方式写入 |
| `SaveMode.Overwrite` | 数据以覆盖的方式写入 |
| `SaveMode.Ignore` | 如果给定的路径已经存在文件,则不做任何操作 |
## 二、CSV
CSV 是一种常见的文本文件格式,其中每一行表示一条记录,记录中的每个字段用逗号分隔。
### 2.1 读取CSV文件
自动推断类型读取读取示例:
```scala
spark.read.format("csv")
.option("header", "false") // 文件中的第一行是否为列的名称
.option("mode", "FAILFAST") // 是否快速失败
.option("inferSchema", "true") // 是否自动推断 schema
.load("/usr/file/csv/dept.csv")
.show()
```
使用预定义类型:
```scala
import org.apache.spark.sql.types.{StructField, StructType, StringType,LongType}
//预定义数据格式
val myManualSchema = new StructType(Array(
StructField("deptno", LongType, nullable = false),
StructField("dname", StringType,nullable = true),
StructField("loc", StringType,nullable = true)
))
spark.read.format("csv")
.option("mode", "FAILFAST")
.schema(myManualSchema)
.load("/usr/file/csv/dept.csv")
.show()
```
### 2.2 写入CSV文件
```scala
df.write.format("csv").mode("overwrite").save("/tmp/csv/dept2")
```
也可以指定具体的分隔符:
```scala
df.write.format("csv").mode("overwrite").option("sep", "\t").save("/tmp/csv/dept2")
```
### 2.3 可选配置
为节省主文篇幅,所有读写配置项见文末 9.1 小节。
## 三、JSON
### 3.1 读取JSON文件
```json
spark.read.format("json").option("mode", "FAILFAST").load("/usr/file/json/dept.json").show(5)
```
需要注意的是:默认不支持一条数据记录跨越多行 (如下),可以通过配置 `multiLine` 为 `true` 来进行更改,其默认值为 `false`。
```json
// 默认支持单行
{"DEPTNO": 10,"DNAME": "ACCOUNTING","LOC": "NEW YORK"}
//默认不支持多行
{
"DEPTNO": 10,
"DNAME": "ACCOUNTING",
"LOC": "NEW YORK"
}
```
### 3.2 写入JSON文件
```scala
df.write.format("json").mode("overwrite").save("/tmp/spark/json/dept")
```
### 3.3 可选配置
为节省主文篇幅,所有读写配置项见文末 9.2 小节。
## 四、Parquet
Parquet 是一个开源的面向列的数据存储,它提供了多种存储优化,允许读取单独的列非整个文件,这不仅节省了存储空间而且提升了读取效率,它是 Spark 是默认的文件格式。
### 4.1 读取Parquet文件
```scala
spark.read.format("parquet").load("/usr/file/parquet/dept.parquet").show(5)
```
### 2.2 写入Parquet文件
```scala
df.write.format("parquet").mode("overwrite").save("/tmp/spark/parquet/dept")
```
### 2.3 可选配置
Parquet 文件有着自己的存储规则,因此其可选配置项比较少,常用的有如下两个:
| 读写操作 | 配置项 | 可选值 | 默认值 | 描述 |
| -------- | -------------------- | ------------------------------------------------------------ | ------------------------------------------- | ------------------------------------------------------------ |
| Write | compression or codec | None,
uncompressed,
bzip2,
deflate, gzip,
lz4, or snappy | None | 压缩文件格式 |
| Read | mergeSchema | true, false | 取决于配置项 `spark.sql.parquet.mergeSchema` | 当为真时,Parquet 数据源将所有数据文件收集的 Schema 合并在一起,否则将从摘要文件中选择 Schema,如果没有可用的摘要文件,则从随机数据文件中选择 Schema。 |
> 更多可选配置可以参阅官方文档:https://spark.apache.org/docs/latest/sql-data-sources-parquet.html
## 五、ORC
ORC 是一种自描述的、类型感知的列文件格式,它针对大型数据的读写进行了优化,也是大数据中常用的文件格式。
### 5.1 读取ORC文件
```scala
spark.read.format("orc").load("/usr/file/orc/dept.orc").show(5)
```
### 4.2 写入ORC文件
```scala
csvFile.write.format("orc").mode("overwrite").save("/tmp/spark/orc/dept")
```
## 六、SQL Databases
Spark 同样支持与传统的关系型数据库进行数据读写。但是 Spark 程序默认是没有提供数据库驱动的,所以在使用前需要将对应的数据库驱动上传到安装目录下的 `jars` 目录中。下面示例使用的是 Mysql 数据库,使用前需要将对应的 `mysql-connector-java-x.x.x.jar` 上传到 `jars` 目录下。
### 6.1 读取数据
读取全表数据示例如下,这里的 `help_keyword` 是 mysql 内置的字典表,只有 `help_keyword_id` 和 `name` 两个字段。
```scala
spark.read
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver") //驱动
.option("url", "jdbc:mysql://127.0.0.1:3306/mysql") //数据库地址
.option("dbtable", "help_keyword") //表名
.option("user", "root").option("password","root").load().show(10)
```
从查询结果读取数据:
```scala
val pushDownQuery = """(SELECT * FROM help_keyword WHERE help_keyword_id <20) AS help_keywords"""
spark.read.format("jdbc")
.option("url", "jdbc:mysql://127.0.0.1:3306/mysql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root").option("password", "root")
.option("dbtable", pushDownQuery)
.load().show()
//输出
+---------------+-----------+
|help_keyword_id| name|
+---------------+-----------+
| 0| <>|
| 1| ACTION|
| 2| ADD|
| 3|AES_DECRYPT|
| 4|AES_ENCRYPT|
| 5| AFTER|
| 6| AGAINST|
| 7| AGGREGATE|
| 8| ALGORITHM|
| 9| ALL|
| 10| ALTER|
| 11| ANALYSE|
| 12| ANALYZE|
| 13| AND|
| 14| ARCHIVE|
| 15| AREA|
| 16| AS|
| 17| ASBINARY|
| 18| ASC|
| 19| ASTEXT|
+---------------+-----------+
```
也可以使用如下的写法进行数据的过滤:
```scala
val props = new java.util.Properties
props.setProperty("driver", "com.mysql.jdbc.Driver")
props.setProperty("user", "root")
props.setProperty("password", "root")
val predicates = Array("help_keyword_id < 10 OR name = 'WHEN'") //指定数据过滤条件
spark.read.jdbc("jdbc:mysql://127.0.0.1:3306/mysql", "help_keyword", predicates, props).show()
//输出:
+---------------+-----------+
|help_keyword_id| name|
+---------------+-----------+
| 0| <>|
| 1| ACTION|
| 2| ADD|
| 3|AES_DECRYPT|
| 4|AES_ENCRYPT|
| 5| AFTER|
| 6| AGAINST|
| 7| AGGREGATE|
| 8| ALGORITHM|
| 9| ALL|
| 604| WHEN|
+---------------+-----------+
```
可以使用 `numPartitions` 指定读取数据的并行度:
```scala
option("numPartitions", 10)
```
在这里,除了可以指定分区外,还可以设置上界和下界,任何小于下界的值都会被分配在第一个分区中,任何大于上界的值都会被分配在最后一个分区中。
```scala
val colName = "help_keyword_id" //用于判断上下界的列
val lowerBound = 300L //下界
val upperBound = 500L //上界
val numPartitions = 10 //分区综述
val jdbcDf = spark.read.jdbc("jdbc:mysql://127.0.0.1:3306/mysql","help_keyword",
colName,lowerBound,upperBound,numPartitions,props)
```
想要验证分区内容,可以使用 `mapPartitionsWithIndex` 这个算子,代码如下:
```scala
jdbcDf.rdd.mapPartitionsWithIndex((index, iterator) => {
val buffer = new ListBuffer[String]
while (iterator.hasNext) {
buffer.append(index + "分区:" + iterator.next())
}
buffer.toIterator
}).foreach(println)
```
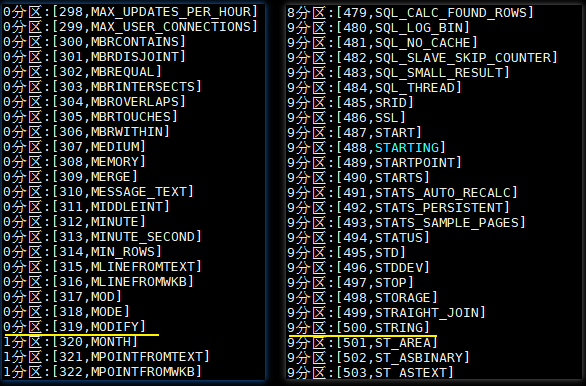
执行结果如下:`help_keyword` 这张表只有 600 条左右的数据,本来数据应该均匀分布在 10 个分区,但是 0 分区里面却有 319 条数据,这是因为设置了下限,所有小于 300 的数据都会被限制在第一个分区,即 0 分区。同理所有大于 500 的数据被分配在 9 分区,即最后一个分区。
### 6.2 写入数据
```scala
val df = spark.read.format("json").load("/usr/file/json/emp.json")
df.write
.format("jdbc")
.option("url", "jdbc:mysql://127.0.0.1:3306/mysql")
.option("user", "root").option("password", "root")
.option("dbtable", "emp")
.save()
```
## 七、Text
Text 文件在读写性能方面并没有任何优势,且不能表达明确的数据结构,所以其使用的比较少,读写操作如下:
### 7.1 读取Text数据
```scala
spark.read.textFile("/usr/file/txt/dept.txt").show()
```
### 7.2 写入Text数据
```scala
df.write.text("/tmp/spark/txt/dept")
```
## 八、数据读写高级特性
### 8.1 并行读
多个 Executors 不能同时读取同一个文件,但它们可以同时读取不同的文件。这意味着当您从一个包含多个文件的文件夹中读取数据时,这些文件中的每一个都将成为 DataFrame 中的一个分区,并由可用的 Executors 并行读取。
### 8.2 并行写
写入的文件或数据的数量取决于写入数据时 DataFrame 拥有的分区数量。默认情况下,每个数据分区写一个文件。
### 8.3 分区写入
分区和分桶这两个概念和 Hive 中分区表和分桶表是一致的。都是将数据按照一定规则进行拆分存储。需要注意的是 `partitionBy` 指定的分区和 RDD 中分区不是一个概念:这里的**分区表现为输出目录的子目录**,数据分别存储在对应的子目录中。
```scala
val df = spark.read.format("json").load("/usr/file/json/emp.json")
df.write.mode("overwrite").partitionBy("deptno").save("/tmp/spark/partitions")
```
输出结果如下:可以看到输出被按照部门编号分为三个子目录,子目录中才是对应的输出文件。
### 8.3 分桶写入
分桶写入就是将数据按照指定的列和桶数进行散列,目前分桶写入只支持保存为表,实际上这就是 Hive 的分桶表。
```scala
val numberBuckets = 10
val columnToBucketBy = "empno"
df.write.format("parquet").mode("overwrite")
.bucketBy(numberBuckets, columnToBucketBy).saveAsTable("bucketedFiles")
```
### 8.5 文件大小管理
如果写入产生小文件数量过多,这时会产生大量的元数据开销。Spark 和 HDFS 一样,都不能很好的处理这个问题,这被称为“small file problem”。同时数据文件也不能过大,否则在查询时会有不必要的性能开销,因此要把文件大小控制在一个合理的范围内。
在上文我们已经介绍过可以通过分区数量来控制生成文件的数量,从而间接控制文件大小。Spark 2.2 引入了一种新的方法,以更自动化的方式控制文件大小,这就是 `maxRecordsPerFile` 参数,它允许你通过控制写入文件的记录数来控制文件大小。
```scala
// Spark 将确保文件最多包含 5000 条记录
df.write.option(“maxRecordsPerFile”, 5000)
```
## 九、可选配置附录
### 9.1 CSV读写可选配置
| 读\写操作 | 配置项 | 可选值 | 默认值 | 描述 |
| --------- | --------------------------- | ------------------------------------------------------------ | -------------------------- | ------------------------------------------------------------ |
| Both | seq | 任意字符 | `,`(逗号) | 分隔符 |
| Both | header | true, false | false | 文件中的第一行是否为列的名称。 |
| Read | escape | 任意字符 | \ | 转义字符 |
| Read | inferSchema | true, false | false | 是否自动推断列类型 |
| Read | ignoreLeadingWhiteSpace | true, false | false | 是否跳过值前面的空格 |
| Both | ignoreTrailingWhiteSpace | true, false | false | 是否跳过值后面的空格 |
| Both | nullValue | 任意字符 | “” | 声明文件中哪个字符表示空值 |
| Both | nanValue | 任意字符 | NaN | 声明哪个值表示 NaN 或者缺省值 |
| Both | positiveInf | 任意字符 | Inf | 正无穷 |
| Both | negativeInf | 任意字符 | -Inf | 负无穷 |
| Both | compression or codec | None,
uncompressed,
bzip2, deflate,
gzip, lz4, or
snappy | none | 文件压缩格式 |
| Both | dateFormat | 任何能转换为 Java 的
SimpleDataFormat 的字符串 | yyyy-MM-dd | 日期格式 |
| Both | timestampFormat | 任何能转换为 Java 的
SimpleDataFormat 的字符串 | yyyy-MMdd’T’HH:mm:ss.SSSZZ | 时间戳格式 |
| Read | maxColumns | 任意整数 | 20480 | 声明文件中的最大列数 |
| Read | maxCharsPerColumn | 任意整数 | 1000000 | 声明一个列中的最大字符数。 |
| Read | escapeQuotes | true, false | true | 是否应该转义行中的引号。 |
| Read | maxMalformedLogPerPartition | 任意整数 | 10 | 声明每个分区中最多允许多少条格式错误的数据,超过这个值后格式错误的数据将不会被读取 |
| Write | quoteAll | true, false | false | 指定是否应该将所有值都括在引号中,而不只是转义具有引号字符的值。 |
| Read | multiLine | true, false | false | 是否允许每条完整记录跨域多行 |
### 9.2 JSON读写可选配置
| 读\写操作 | 配置项 | 可选值 | 默认值 |
| --------- | ---------------------------------- | ------------------------------------------------------------ | -------------------------------- |
| Both | compression or codec | None,
uncompressed,
bzip2, deflate,
gzip, lz4, or
snappy | none |
| Both | dateFormat | 任何能转换为 Java 的 SimpleDataFormat 的字符串 | yyyy-MM-dd |
| Both | timestampFormat | 任何能转换为 Java 的 SimpleDataFormat 的字符串 | yyyy-MMdd’T’HH:mm:ss.SSSZZ |
| Read | primitiveAsString | true, false | false |
| Read | allowComments | true, false | false |
| Read | allowUnquotedFieldNames | true, false | false |
| Read | allowSingleQuotes | true, false | true |
| Read | allowNumericLeadingZeros | true, false | false |
| Read | allowBackslashEscapingAnyCharacter | true, false | false |
| Read | columnNameOfCorruptRecord | true, false | Value of spark.sql.column&NameOf |
| Read | multiLine | true, false | false |
### 9.3 数据库读写可选配置
| 属性名称 | 含义 |
| ------------------------------------------ | ------------------------------------------------------------ |
| url | 数据库地址 |
| dbtable | 表名称 |
| driver | 数据库驱动 |
| partitionColumn,
lowerBound, upperBoun | 分区总数,上界,下界 |
| numPartitions | 可用于表读写并行性的最大分区数。如果要写的分区数量超过这个限制,那么可以调用 coalesce(numpartition) 重置分区数。 |
| fetchsize | 每次往返要获取多少行数据。此选项仅适用于读取数据。 |
| batchsize | 每次往返插入多少行数据,这个选项只适用于写入数据。默认值是 1000。 |
| isolationLevel | 事务隔离级别:可以是 NONE,READ_COMMITTED, READ_UNCOMMITTED,REPEATABLE_READ 或 SERIALIZABLE,即标准事务隔离级别。
默认值是 READ_UNCOMMITTED。这个选项只适用于数据读取。 |
| createTableOptions | 写入数据时自定义创建表的相关配置 |
| createTableColumnTypes | 写入数据时自定义创建列的列类型 |
> 数据库读写更多配置可以参阅官方文档:https://spark.apache.org/docs/latest/sql-data-sources-jdbc.html
## 参考资料
1. Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02
2. https://spark.apache.org/docs/latest/sql-data-sources.html