# Sqoop基本使用
## 一、Sqoop 基本命令
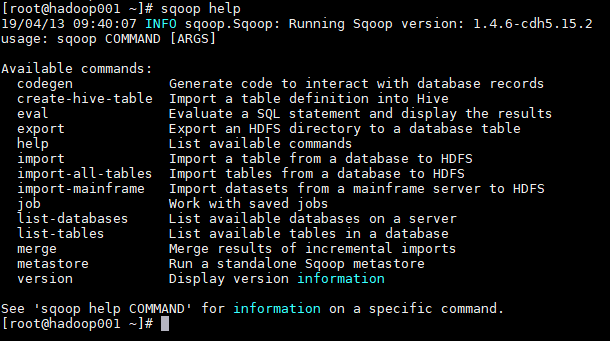
### 1. 查看所有命令
```shell
# sqoop help
```
### 2. 查看某条命令的具体使用方法
```shell
# sqoop help 命令名
```
## 二、Sqoop 与 MySQL
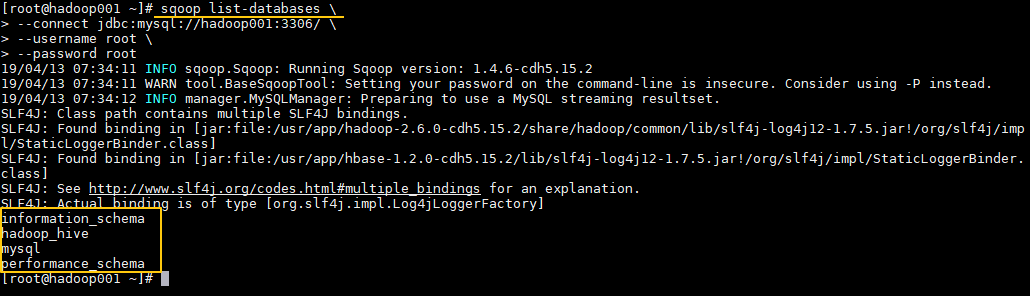
### 1. 查询MySQL所有数据库
通常用于 Sqoop 与 MySQL 连通测试:
```shell
sqoop list-databases \
--connect jdbc:mysql://hadoop001:3306/ \
--username root \
--password root
```
### 2. 查询指定数据库中所有数据表
```shell
sqoop list-tables \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root
```
## 三、Sqoop 与 HDFS
### 3.1 MySQL数据导入到HDFS
#### 1. 导入命令
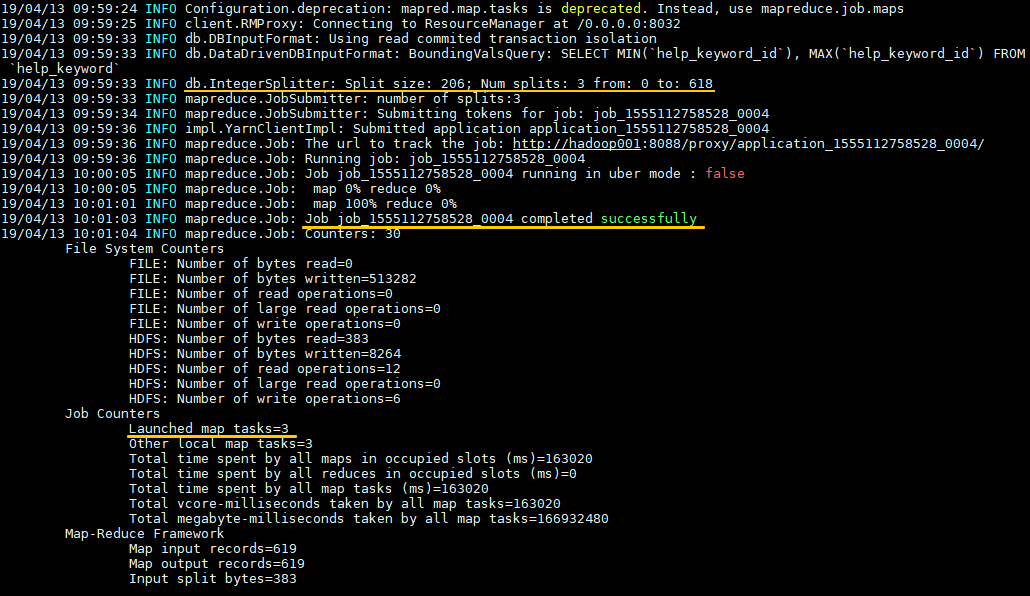
示例:导出 MySQL 数据库中的 `help_keyword` 表到 HDFS 的 `/sqoop` 目录下,如果导入目录存在则先删除再导入,使用 3 个 `map tasks` 并行导入。
> 注:help_keyword 是 MySQL 内置的一张字典表,之后的示例均使用这张表。
```shell
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待导入的表
--delete-target-dir \ # 目标目录存在则先删除
--target-dir /sqoop \ # 导入的目标目录
--fields-terminated-by '\t' \ # 指定导出数据的分隔符
-m 3 # 指定并行执行的 map tasks 数量
```
日志输出如下,可以看到输入数据被平均 `split` 为三份,分别由三个 `map task` 进行处理。数据默认以表的主键列作为拆分依据,如果你的表没有主键,有以下两种方案:
+ 添加 `-- autoreset-to-one-mapper` 参数,代表只启动一个 `map task`,即不并行执行;
+ 若仍希望并行执行,则可以使用 `--split-by ` 指明拆分数据的参考列。
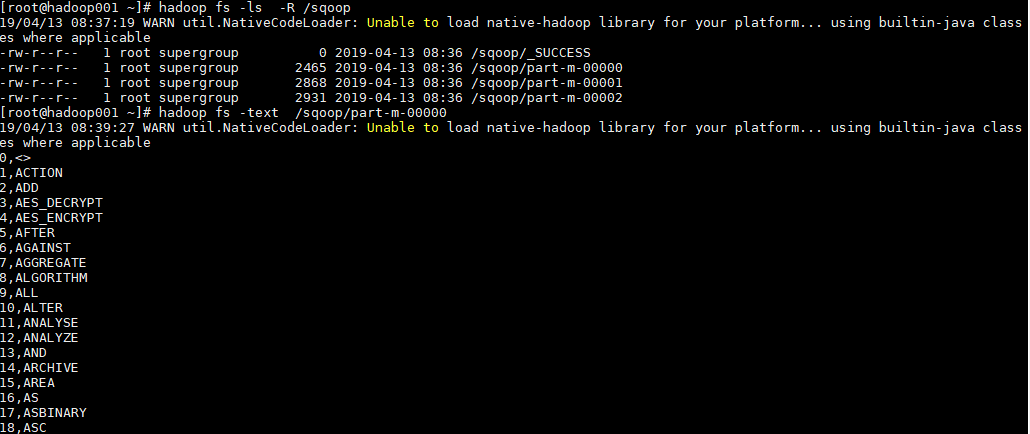
#### 2. 导入验证
```shell
# 查看导入后的目录
hadoop fs -ls -R /sqoop
# 查看导入内容
hadoop fs -text /sqoop/part-m-00000
```
查看 HDFS 导入目录,可以看到表中数据被分为 3 部分进行存储,这是由指定的并行度决定的。
### 3.2 HDFS数据导出到MySQL
```shell
sqoop export \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword_from_hdfs \ # 导出数据存储在 MySQL 的 help_keyword_from_hdf 的表中
--export-dir /sqoop \
--input-fields-terminated-by '\t'\
--m 3
```
表必须预先创建,建表语句如下:
```sql
CREATE TABLE help_keyword_from_hdfs LIKE help_keyword ;
```
## 四、Sqoop 与 Hive
### 4.1 MySQL数据导入到Hive
Sqoop 导入数据到 Hive 是通过先将数据导入到 HDFS 上的临时目录,然后再将数据从 HDFS 上 `Load` 到 Hive 中,最后将临时目录删除。可以使用 `target-dir` 来指定临时目录。
#### 1. 导入命令
```shell
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待导入的表
--delete-target-dir \ # 如果临时目录存在删除
--target-dir /sqoop_hive \ # 临时目录位置
--hive-database sqoop_test \ # 导入到 Hive 的 sqoop_test 数据库,数据库需要预先创建。不指定则默认为 default 库
--hive-import \ # 导入到 Hive
--hive-overwrite \ # 如果 Hive 表中有数据则覆盖,这会清除表中原有的数据,然后再写入
-m 3 # 并行度
```
导入到 Hive 中的 `sqoop_test` 数据库需要预先创建,不指定则默认使用 Hive 中的 `default` 库。
```shell
# 查看 hive 中的所有数据库
hive> SHOW DATABASES;
# 创建 sqoop_test 数据库
hive> CREATE DATABASE sqoop_test;
```
#### 2. 导入验证
```shell
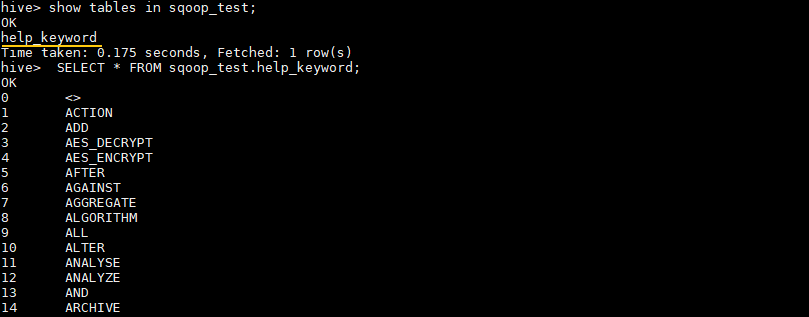
# 查看 sqoop_test 数据库的所有表
hive> SHOW TABLES IN sqoop_test;
# 查看表中数据
hive> SELECT * FROM sqoop_test.help_keyword;
```
#### 3. 可能出现的问题
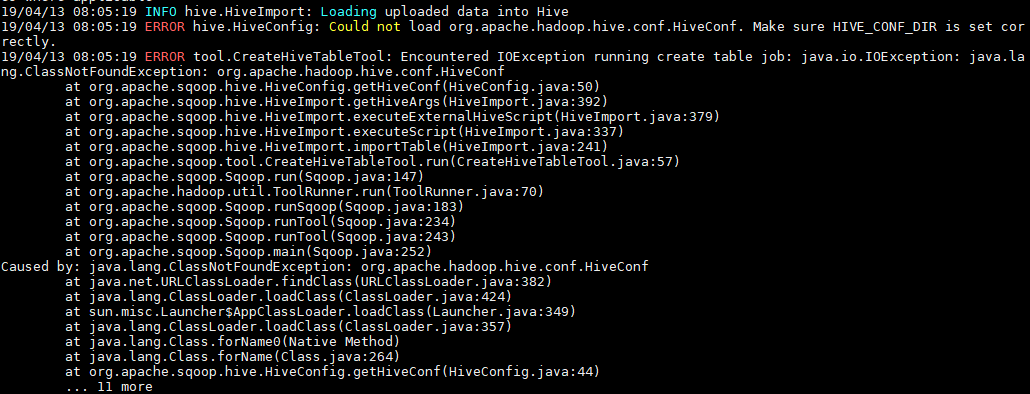
如果执行报错 `java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf`,则需将 Hive 安装目录下 `lib` 下的 `hive-exec-**.jar` 放到 sqoop 的 `lib` 。
```shell
[root@hadoop001 lib]# ll hive-exec-*
-rw-r--r--. 1 1106 4001 19632031 11 月 13 21:45 hive-exec-1.1.0-cdh5.15.2.jar
[root@hadoop001 lib]# cp hive-exec-1.1.0-cdh5.15.2.jar ${SQOOP_HOME}/lib
```
### 4.2 Hive 导出数据到MySQL
由于 Hive 的数据是存储在 HDFS 上的,所以 Hive 导入数据到 MySQL,实际上就是 HDFS 导入数据到 MySQL。
#### 1. 查看Hive表在HDFS的存储位置
```shell
# 进入对应的数据库
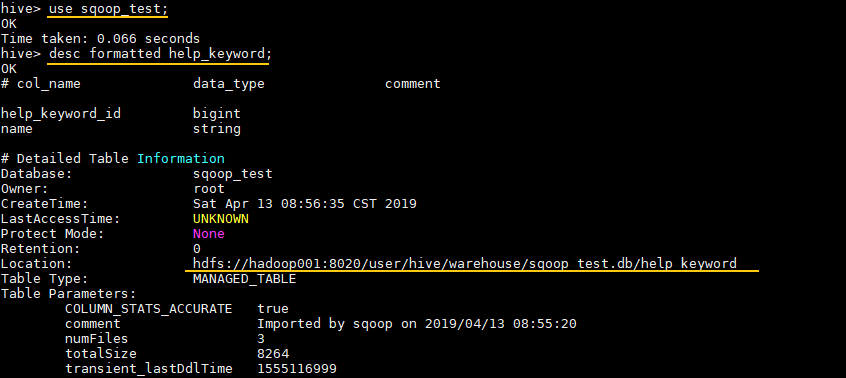
hive> use sqoop_test;
# 查看表信息
hive> desc formatted help_keyword;
```
`Location` 属性为其存储位置:
这里可以查看一下这个目录,文件结构如下:

#### 3.2 执行导出命令
```shell
sqoop export \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword_from_hive \
--export-dir /user/hive/warehouse/sqoop_test.db/help_keyword \
-input-fields-terminated-by '\001' \ # 需要注意的是 hive 中默认的分隔符为 \001
--m 3
```
MySQL 中的表需要预先创建:
```sql
CREATE TABLE help_keyword_from_hive LIKE help_keyword ;
```
## 五、Sqoop 与 HBase
> 本小节只讲解从 RDBMS 导入数据到 HBase,因为暂时没有命令能够从 HBase 直接导出数据到 RDBMS。
### 5.1 MySQL导入数据到HBase
#### 1. 导入数据
将 `help_keyword` 表中数据导入到 HBase 上的 `help_keyword_hbase` 表中,使用原表的主键 `help_keyword_id` 作为 `RowKey`,原表的所有列都会在 `keywordInfo` 列族下,目前只支持全部导入到一个列族下,不支持分别指定列族。
```shell
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待导入的表
--hbase-table help_keyword_hbase \ # hbase 表名称,表需要预先创建
--column-family keywordInfo \ # 所有列导入到 keywordInfo 列族下
--hbase-row-key help_keyword_id # 使用原表的 help_keyword_id 作为 RowKey
```
导入的 HBase 表需要预先创建:
```shell
# 查看所有表
hbase> list
# 创建表
hbase> create 'help_keyword_hbase', 'keywordInfo'
# 查看表信息
hbase> desc 'help_keyword_hbase'
```
#### 2. 导入验证
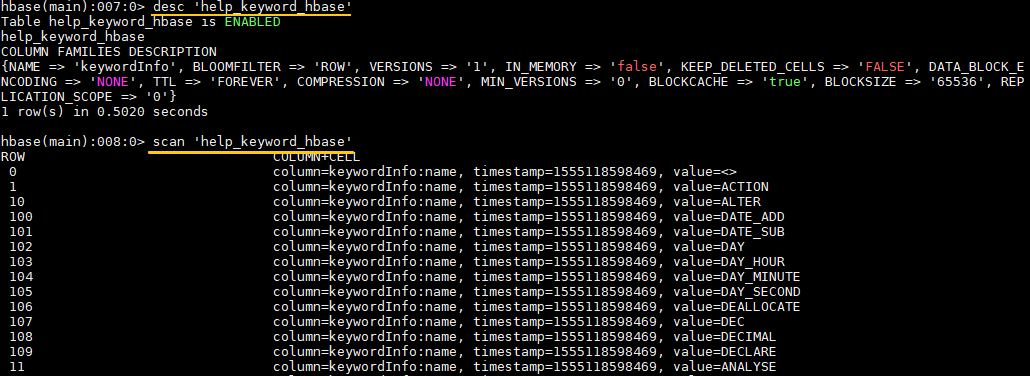
使用 `scan` 查看表数据:
## 六、全库导出
Sqoop 支持通过 `import-all-tables` 命令进行全库导出到 HDFS/Hive,但需要注意有以下两个限制:
+ 所有表必须有主键;或者使用 `--autoreset-to-one-mapper`,代表只启动一个 `map task`;
+ 你不能使用非默认的分割列,也不能通过 WHERE 子句添加任何限制。
> 第二点解释得比较拗口,这里列出官方原本的说明:
>
> + You must not intend to use non-default splitting column, nor impose any conditions via a `WHERE` clause.
全库导出到 HDFS:
```shell
sqoop import-all-tables \
--connect jdbc:mysql://hadoop001:3306/数据库名 \
--username root \
--password root \
--warehouse-dir /sqoop_all \ # 每个表会单独导出到一个目录,需要用此参数指明所有目录的父目录
--fields-terminated-by '\t' \
-m 3
```
全库导出到 Hive:
```shell
sqoop import-all-tables -Dorg.apache.sqoop.splitter.allow_text_splitter=true \
--connect jdbc:mysql://hadoop001:3306/数据库名 \
--username root \
--password root \
--hive-database sqoop_test \ # 导出到 Hive 对应的库
--hive-import \
--hive-overwrite \
-m 3
```
## 七、Sqoop 数据过滤
### 7.1 query参数
Sqoop 支持使用 `query` 参数定义查询 SQL,从而可以导出任何想要的结果集。使用示例如下:
```shell
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--query 'select * from help_keyword where $CONDITIONS and help_keyword_id < 50' \
--delete-target-dir \
--target-dir /sqoop_hive \
--hive-database sqoop_test \ # 指定导入目标数据库 不指定则默认使用 Hive 中的 default 库
--hive-table filter_help_keyword \ # 指定导入目标表
--split-by help_keyword_id \ # 指定用于 split 的列
--hive-import \ # 导入到 Hive
--hive-overwrite \ 、
-m 3
```
在使用 `query` 进行数据过滤时,需要注意以下三点:
+ 必须用 `--hive-table` 指明目标表;
+ 如果并行度 `-m` 不为 1 或者没有指定 `--autoreset-to-one-mapper`,则需要用 ` --split-by ` 指明参考列;
+ SQL 的 `where` 字句必须包含 `$CONDITIONS`,这是固定写法,作用是动态替换。
### 7.2 增量导入
```shell
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \
--target-dir /sqoop_hive \
--hive-database sqoop_test \
--incremental append \ # 指明模式
--check-column help_keyword_id \ # 指明用于增量导入的参考列
--last-value 300 \ # 指定参考列上次导入的最大值
--hive-import \
-m 3
```
`incremental` 参数有以下两个可选的选项:
+ **append**:要求参考列的值必须是递增的,所有大于 `last-value` 的值都会被导入;
+ **lastmodified**:要求参考列的值必须是 `timestamp` 类型,且插入数据时候要在参考列插入当前时间戳,更新数据时也要更新参考列的时间戳,所有时间晚于 ``last-value`` 的数据都会被导入。
通过上面的解释我们可以看出来,其实 Sqoop 的增量导入并没有太多神器的地方,就是依靠维护的参考列来判断哪些是增量数据。当然我们也可以使用上面介绍的 `query` 参数来进行手动的增量导出,这样反而更加灵活。
## 八、类型支持
Sqoop 默认支持数据库的大多数字段类型,但是某些特殊类型是不支持的。遇到不支持的类型,程序会抛出异常 `Hive does not support the SQL type for column xxx` 异常,此时可以通过下面两个参数进行强制类型转换:
+ **--map-column-java\** :重写 SQL 到 Java 类型的映射;
+ **--map-column-hive \** : 重写 Hive 到 Java 类型的映射。
示例如下,将原先 `id` 字段强制转为 String 类型,`value` 字段强制转为 Integer 类型:
```
$ sqoop import ... --map-column-java id=String,value=Integer
```
## 参考资料
[Sqoop User Guide (v1.4.7)](http://sqoop.apache.org/docs/1.4.7/SqoopUserGuide.html)