# Spark开发环境搭建
## 一、安装Spark
### 1.1 下载并解压
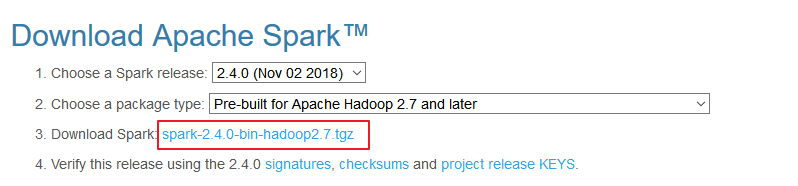
官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载:
解压安装包:
```shell
# tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz
```
### 1.2 配置环境变量
```shell
# vim /etc/profile
```
添加环境变量:
```shell
export SPARK_HOME=/usr/app/spark-2.2.3-bin-hadoop2.6
export PATH=${SPARK_HOME}/bin:$PATH
```
使得配置的环境变量立即生效:
```shell
# source /etc/profile
```
### 1.3 Local模式
Local 模式是最简单的一种运行方式,它采用单节点多线程方式运行,不用部署,开箱即用,适合日常测试开发。
```shell
# 启动spark-shell
spark-shell --master local[2]
```
- **local**:只启动一个工作线程;
- **local[k]**:启动 k 个工作线程;
- **local[*]**:启动跟 cpu 数目相同的工作线程数。
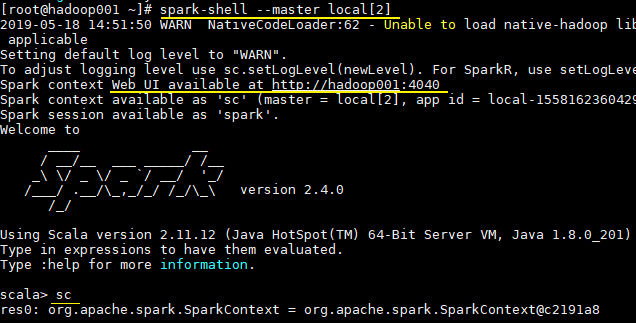
进入 spark-shell 后,程序已经自动创建好了上下文 `SparkContext`,等效于执行了下面的 Scala 代码:
```scala
val conf = new SparkConf().setAppName("Spark shell").setMaster("local[2]")
val sc = new SparkContext(conf)
```
## 二、词频统计案例
安装完成后可以先做一个简单的词频统计例子,感受 spark 的魅力。准备一个词频统计的文件样本 `wc.txt`,内容如下:
```txt
hadoop,spark,hadoop
spark,flink,flink,spark
hadoop,hadoop
```
在 scala 交互式命令行中执行如下 Scala 语句:
```scala
val file = spark.sparkContext.textFile("file:///usr/app/wc.txt")
val wordCounts = file.flatMap(line => line.split(",")).map((word => (word, 1))).reduceByKey(_ + _)
wordCounts.collect
```
执行过程如下,可以看到已经输出了词频统计的结果:
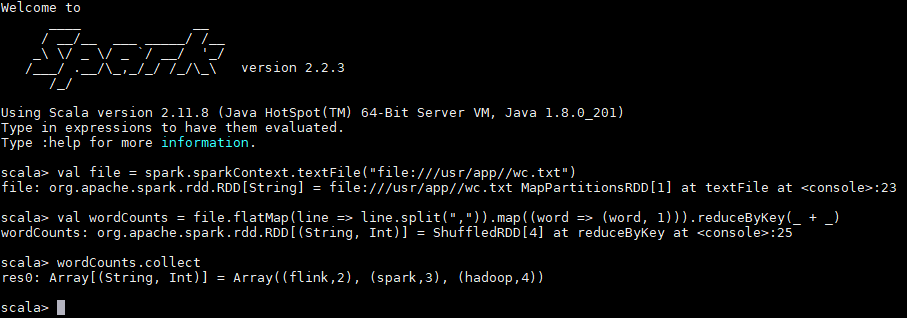
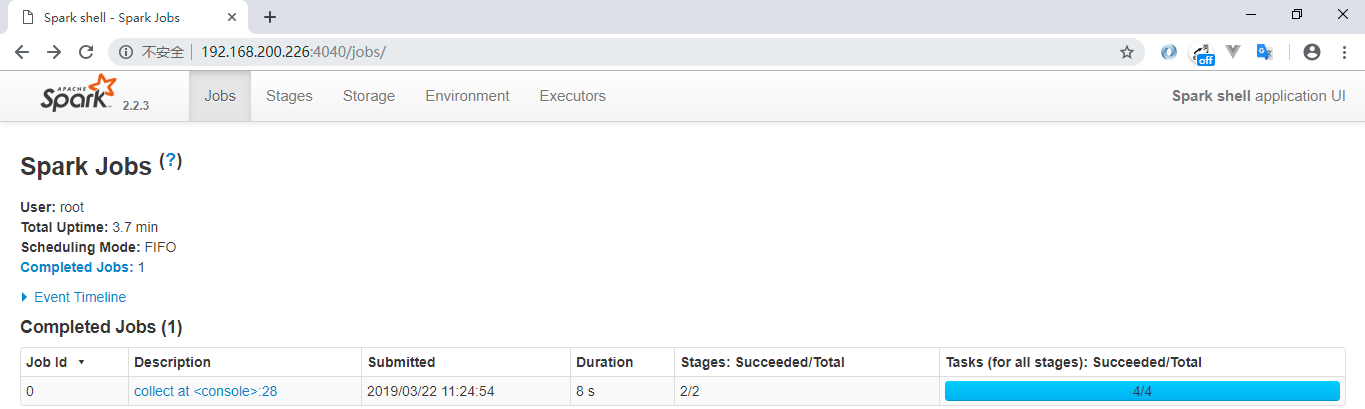
同时还可以通过 Web UI 查看作业的执行情况,访问端口为 `4040`:
## 三、Scala开发环境配置
Spark 是基于 Scala 语言进行开发的,分别提供了基于 Scala、Java、Python 语言的 API,如果你想使用 Scala 语言进行开发,则需要搭建 Scala 语言的开发环境。
### 3.1 前置条件
Scala 的运行依赖于 JDK,所以需要你本机有安装对应版本的 JDK,最新的 Scala 2.12.x 需要 JDK 1.8+。
### 3.2 安装Scala插件
IDEA 默认不支持 Scala 语言的开发,需要通过插件进行扩展。打开 IDEA,依次点击 **File** => **settings**=> **plugins** 选项卡,搜索 Scala 插件 (如下图)。找到插件后进行安装,并重启 IDEA 使得安装生效。
### 3.3 创建Scala项目
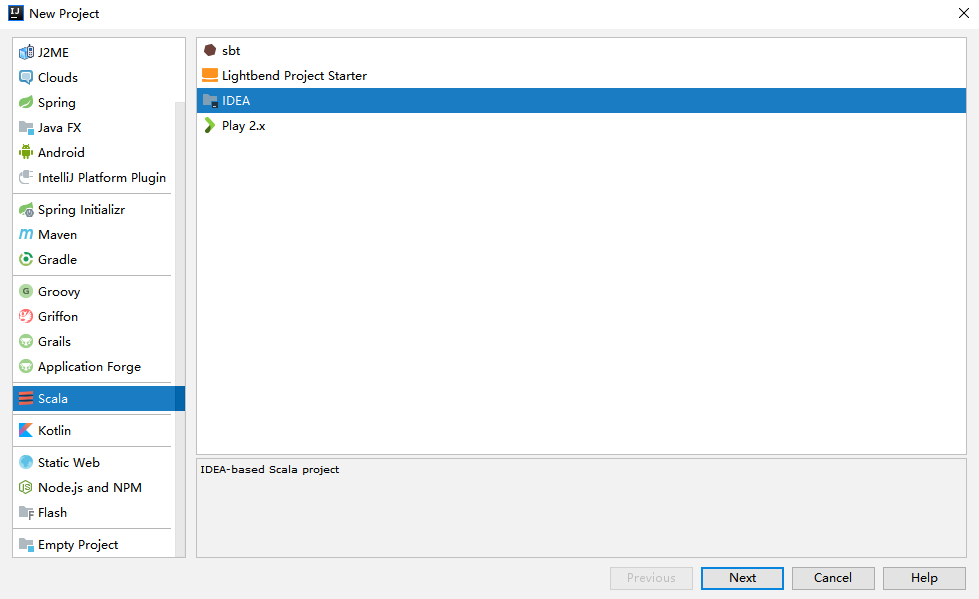
在 IDEA 中依次点击 **File** => **New** => **Project** 选项卡,然后选择创建 `Scala—IDEA` 工程:
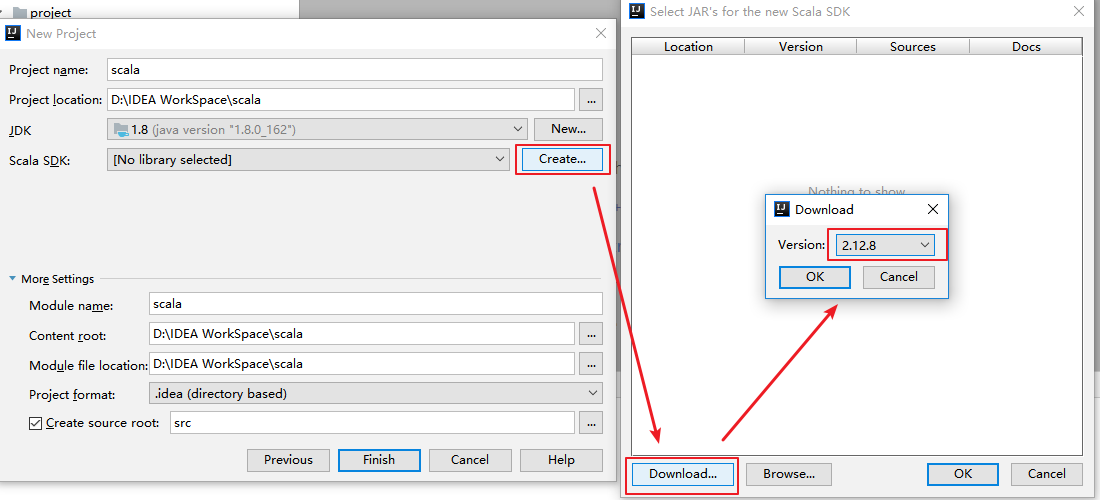
### 3.4 下载Scala SDK
#### 1. 方式一
此时看到 `Scala SDK` 为空,依次点击 `Create` => `Download` ,选择所需的版本后,点击 `OK` 按钮进行下载,下载完成点击 `Finish` 进入工程。
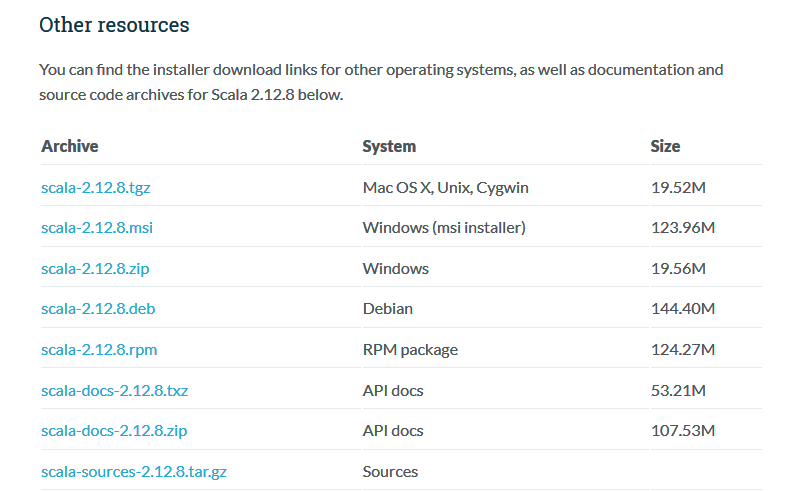
#### 2. 方式二
方式一是 Scala 官方安装指南里使用的方式,但下载速度通常比较慢,且这种安装下并没有直接提供 Scala 命令行工具。所以个人推荐到官网下载安装包进行安装,下载地址:https://www.scala-lang.org/download/
这里我的系统是 Windows,下载 msi 版本的安装包后,一直点击下一步进行安装,安装完成后会自动配置好环境变量。
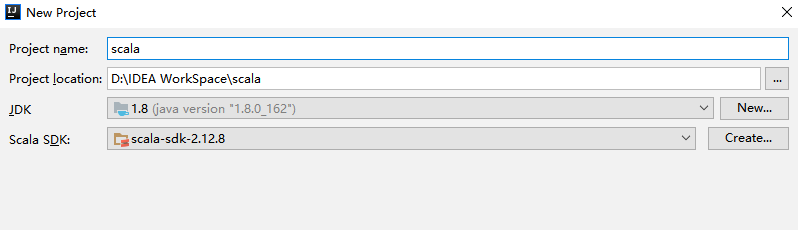
由于安装时已经自动配置好环境变量,所以 IDEA 会自动选择对应版本的 SDK。
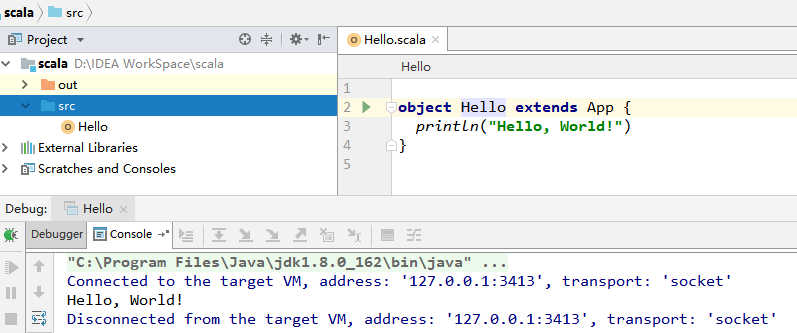
### 3.5 创建Hello World
在工程 `src` 目录上右击 **New** => **Scala class** 创建 `Hello.scala`。输入代码如下,完成后点击运行按钮,成功运行则代表搭建成功。
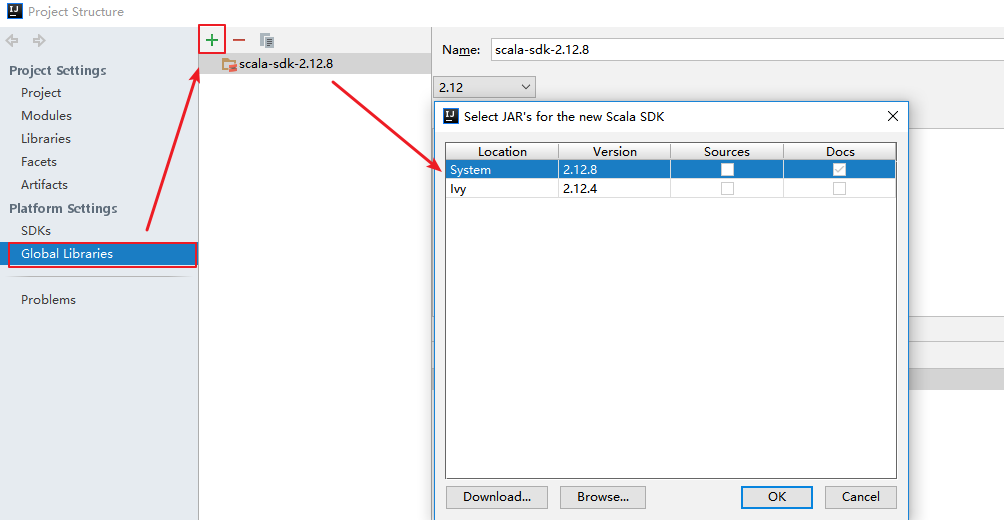
### 3.6 切换Scala版本
在日常的开发中,由于对应软件(如 Spark)的版本切换,可能导致需要切换 Scala 的版本,则可以在 `Project Structures` 中的 `Global Libraries` 选项卡中进行切换。
### 3.7 可能出现的问题
在 IDEA 中有时候重新打开项目后,右击并不会出现新建 `scala` 文件的选项,或者在编写时没有 Scala 语法提示,此时可以先删除 `Global Libraries` 中配置好的 SDK,之后再重新添加:
**另外在 IDEA 中以本地模式运行 Spark 项目是不需要在本机搭建 Spark 和 Hadoop 环境的。**