diff --git a/ldap.md b/ldap.md
new file mode 100644
index 0000000..f48d916
--- /dev/null
+++ b/ldap.md
@@ -0,0 +1,15 @@
+# ldap
+
+#### LDAP简称对应
+
+o– organization(组织-公司)
+ou – organization unit(组织单元-部门)
+c - countryName(国家)
+dc - domainComponent(域名) -- 类比命名空间
+sn – suer name(真实名称) -- 用户的真是名称
+cn - common name(常用名称) -- 类比用户的昵称(全名)
+
+
+
+
+
diff --git a/linux/linux iptables 规则.md b/linux/linux iptables 规则.md
new file mode 100644
index 0000000..14794ad
--- /dev/null
+++ b/linux/linux iptables 规则.md
@@ -0,0 +1,50 @@
+```sh
+#允许 tcp 2181 端口 被192.168.53.151 地址访问
+iptables -A INPUT -p tcp -s 192.168.53.151 --dport 2181 -j ACCEPT
+iptables -A INPUT -p tcp -s 192.168.53.152 --dport 2181 -j ACCEPT
+iptables -A INPUT -p tcp -s 192.168.53.153 --dport 2181 -j ACCEPT
+iptables -A INPUT -p tcp -s 127.0.0.1 --dport 2181 -j ACCEPT
+
+#禁止 tcp 2181 端口 被所有地址访问
+iptables -A INPUT -p tcp -s 0.0.0.0/0 --dport 2181 -j DROP
+
+#备份 iptables 规则
+iptables-save > /etc/sysconfig/iptables
+#还原 iptables 规则
+iptables-restore < 文件名称
+
+#立即生效 iptables 规则
+service iptables save
+```
+
+
+
+
+
+| 参数 | 作用 |
+| ------------- | ---------------------------------------------- |
+| -P | 设置默认策略:iptables -P INPUT (DROP\|ACCEPT) |
+| | FORWARD 转发,INPUT 进站,OUTPUT 出站 |
+| -F | 清空规则链 |
+| -L | 查看规则链 |
+| -A | 在规则链的末尾加入新规则 |
+| -I num | 在规则链的头部加入新规则 |
+| -D num | 删除某一条规则 |
+| -s | 匹配来源地址IP/MASK,加叹号"!"表示除这个IP外。 |
+| -R | 替换防火墙规则 |
+| -Z | 清空防火墙数据表统计信息 |
+| | |
+| -d | 匹配目标地址 |
+| -i 网卡名称 | 匹配从这块网卡流入的数据 |
+| | |
+| -o 网卡名称 | 匹配从这块网卡流出的数据 |
+| -p | 匹配协议,如tcp,udp,icmp |
+| --dport num | 匹配目标端口号 |
+| --sport num | 匹配来源端口号 |
+| --line-number | 行号 显示 |
+
+
+
+
+
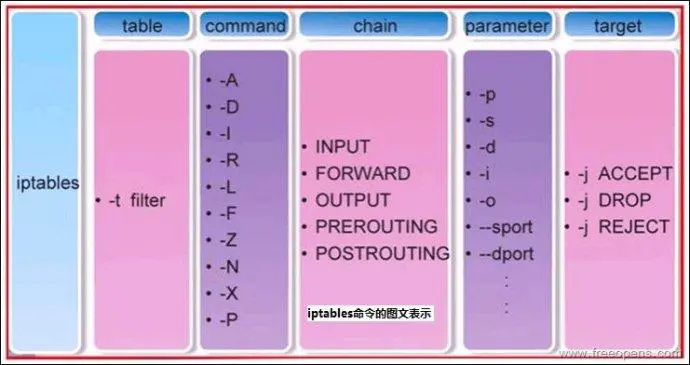
+
\ No newline at end of file
diff --git a/linux/linux 查看日志.md b/linux/linux 查看日志.md
new file mode 100644
index 0000000..48e269f
--- /dev/null
+++ b/linux/linux 查看日志.md
@@ -0,0 +1,301 @@
+# Linux查看日志
+
+在Linux下用VIM打开大小几个G、甚至几十个G的文件时,是非常慢的。
+
+这时,我们可以利用下面的方法分割文件,然后再打开。
+
+
+
+## 查看日志文件
+
+**查看文件的前多少行**
+
+```sh
+head -10000 /var/lib/mysql/slowquery.log > temp.log
+```
+
+上面命令的意思是:把slowquery.log文件前10000行的数据写入到temp.log文件中。
+
+**查看文件的后多少行**
+
+```sh
+tail -10000 /var/lib/mysql/slowquery.log > temp.log
+```
+
+上面命令的意思是:把slowquery.log文件后10000行的数据写入到temp.log文件中。
+
+**查看文件的几行到几行**
+
+```sh
+sed -n '10,10000p' /var/lib/mysql/slowquery.log > temp.log
+```
+
+上面命令的意思是:把slowquery.log文件第10到10000行的数据写入到temp.log文件中。
+
+**根据查询条件导出**
+
+```sh
+cat catalina.log | grep '2017-09-06 15:15:42' > test.log
+```
+
+**根据查询条件导出(上下文)**
+
+显示file文件中匹配keyword字串那行以及上下10行
+
+```sh
+cat catalina.log | grep -C 10 keyword
+#or
+grep -C 10 keyword catalina.out
+```
+
+**显示keyword及前10行**
+
+```sh
+ cat catalina.log | grep -B 10 keyword
+ #or
+ grep -B 10 keyword catalina.out
+```
+
+**显示keyword及后10行**
+
+```sh
+ cat catalina.log | grep -A 10 keyword
+ #or
+ grep -A 10 keyword catalina.out
+```
+
+**实时监控文件输出**
+
+```
+tail -f catalina.out
+```
+
+
+
+## 查看日志文件
+
+查看linux 标准输出
+
+- stdin:`0` 输入
+- stdout:`1` 标准输出
+- stderr:`2` 错误输出
+
+```sh
+ps -aux | grep "service_name"
+
+cd /proc/${pid}/fd/
+
+tail -f 1 #查看标准输出
+tail -f 1 #查看错误输出
+```
+
+
+
+
+
+## 查看服务输出
+
+通过**journalctl** 查看 service 服务的日志
+
+
+
+**journalctl** 常用参数
+
+```sh
+-k 查看内核日志
+-b 查看系统本次启动的日志 0本次 -1上次
+-u 查看指定服务的日志
+-n 指定日志条数
+-f 追踪日志
+--disk-usage 查看当前日志占用磁盘的空间的总大小
+--since
+--until
+-n 指定行数
+```
+
+
+
+
+
+### 案例:
+
+
+
+```sh
+#追踪 service_name 日志
+journalctl -f -u service_name
+
+#查看service_name 历史日志
+journalctl -r -u service_name
+
+```
+
+**.查看内核日志(不显示应用日志)**
+
+```sh
+journalctl -k
+```
+
+**.查看系统本次启动的日志**
+
+```sh
+journalctl -b
+journalctl -b -0
+```
+
+**.查看上一次启动的日志**
+
+需更改设置,如上次系统崩溃,需要查看日志时,就要看上一次的启动日志。
+
+```sh
+journalctl -b -1
+```
+
+**.查看指定时间的日志**
+
+```sh
+journalctl --since="2012-10-30 18:17:16"
+
+journalctl --since "20 minago"
+
+journalctl --since yesterday
+
+journalctl --since"2015-01-10" --until "2015-01-11 03:00"
+
+journalctl --since 09:00 --until"1 hour ago"
+
+journalctl --since"15:15" --until now
+```
+
+**.显示尾部的最新10行日志**
+
+```sh
+journalctl -n
+```
+
+**.显示尾部指定行数的日志**
+
+```sh
+journalctl -n 20
+```
+
+**.实时滚动显示最新日志**
+
+```sh
+journalctl -f
+```
+
+**.查看指定服务的日志**
+
+```sh
+journalctl /usr/lib/systemd/systemd
+```
+
+**.查看指定进程的日志**
+
+```sh
+journalctl _PID=1
+```
+
+**.查看某个路径的脚本的日志**
+
+```sh
+journalctl /usr/bin/bash
+```
+
+**.查看指定用户的日志**
+
+```sh
+journalctl _UID=33 --since today
+```
+
+**.查看某个Unit的日志**
+
+```sh
+journalctl -u nginx.service
+journalctl -u nginx.service --since today
+```
+
+**.实时滚动显示某个Unit的最新日志**
+
+```sh
+journalctl -f -u nginx.service
+```
+
+**.合并显示多个Unit的日志**
+
+```sh
+journalctl -u nginx.service -u php-fpm.service --since today
+```
+
+**查看指定优先级(及其以上级别)的日志**
+
+日志优先级共有8级
+
+```
+0: emerg
+1: alert
+2: crit
+3: err
+4: warning
+5: notice
+6: info
+7: debug
+```
+
+```sh
+journalctl -p err -b
+```
+
+**.不分页标准输出**
+
+日志默认分页输出--no-pager改为正常的标准输出
+
+```sh
+journalctl --no-pager
+```
+
+**.以JSON格式(单行)输出**
+
+JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。易于人阅读和编写。同时也易于机器解析和生成。它基于JavaScriptProgramming Language, Standard ECMA-262 3rd Edition - December 1999的一个子集。JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java,JavaScript, Perl, Python等)。这些特性使JSON成为理想的数据交换语言。
+
+JSON建构于两种结构:
+
+“名称/值”对的集合(A collection ofname/value pairs):不同的语言中,它被理解为对象(object),纪录(record),结构(struct),字典(dictionary),哈希表(hash table),有键列表(keyed list),或者关联数组(associativearray)。
+
+值的有序列表(An ordered list of values):在大部分语言中,它被理解为数组(array)。
+
+这些都是常见的数据结构。事实上大部分现代计算机语言都以某种形式支持它们。这使得一种数据格式在同样基于这些结构的编程语言之间交换成为可能。
+
+例子
+
+以JSON格式(单行)输出
+
+```sh
+journalctl -b -u httpd.service -o json
+```
+
+.以JSON格式(多行)输出,可读性更好,建议选择多行输出
+
+```sh
+journalctl -b -u httpd.service -o json-pretty
+```
+
+**.显示日志占据的硬盘空间**
+
+```sh
+journalctl --disk-usage
+```
+
+**.指定日志文件占据的最大空间**
+
+```sh
+journalctl --vacuum-size=1G
+```
+
+**.指定日志文件保存多久**
+
+```sh
+journalctl --vacuum-time=1years
+```
+
diff --git a/linux/linux使用grep命令.md b/linux/linux使用grep命令.md
new file mode 100644
index 0000000..021046f
--- /dev/null
+++ b/linux/linux使用grep命令.md
@@ -0,0 +1,94 @@
+
+
+## grep 命令 详解
+
+```
+用法:grep [OPTION]... PATTERN [FILE]...
+在每个 FILE 或标准输入中搜索 PATTERN。
+PATTERN 默认是基本正则表达式 (BRE)。
+示例:grep -i 'hello world' menu.h main.c
+
+正则表达式选择和解释:
+ -E, --extended-regexp PATTERN 是扩展正则表达式 (ERE)
+ -F, --fixed-strings PATTERN 是一组换行符分隔的固定字符串
+ -G, --basic-regexp PATTERN 是基本正则表达式 (BRE)
+ -P, --perl-regexp PATTERN 是 Perl 正则表达式
+ -e, --regexp=PATTERN 使用 PATTERN 进行匹配
+ -f, --file=FILE 从 FILE 中获取 PATTERN
+ -i, --ignore-case 忽略大小写区别
+ -w, --word-regexp 强制 PATTERN 只匹配整个单词
+ -x, --line-regexp 强制 PATTERN 只匹配整行
+ -z, --null-data 数据行以 0 字节结尾,而不是换行符
+
+各种各样的:
+ -s, --no-messages 抑制错误消息
+ -v, --invert-match 选择不匹配的行
+ -V, --version 显示版本信息并退出
+ --help 显示此帮助文本并退出
+
+输出控制:
+ -m, --max-count=NUM 在 NUM 个匹配后停止
+ -b, --byte-offset 使用输出行打印字节偏移量
+ -n, --line-number 打印行号和输出行
+ --line-buffered 每行刷新输出
+ -H, --with-filename 打印每个匹配的文件名
+ -h, --no-filename 禁止输出文件名前缀
+ --label=LABEL 使用 LABEL 作为标准输入文件名前缀
+ -o, --only-matching 仅显示与 PATTERN 匹配的行的一部分
+ -q, --quiet, --silent 抑制所有正常输出
+ --binary-files=TYPE 假设二进制文件是 TYPE;
+ TYPE 是“二进制”、“文本”或“不匹配”
+ -a, --text 等价于 --binary-files=text
+ -I 相当于 --binary-files=without-match
+ -d, --directories=ACTION 如何处理目录;
+ ACTION 是“读取”、“递归”或“跳过”
+ -D, --devices=ACTION 如何处理设备、FIFO和套接字;
+ 动作是“阅读”或“跳过”
+ -r, --recursive 像 --directories=recurse
+ -R, --dereference-recursive
+ 同样,但遵循所有符号链接
+ --include=FILE_PATTERN
+ 仅搜索与 FILE_PATTERN 匹配的文件
+ --exclude=FILE_PATTERN
+ 跳过匹配 FILE_PATTERN 的文件和目录
+ --exclude-from=FILE 跳过与 FILE 中任何文件模式匹配的文件
+ --exclude-dir=PATTERN 匹配 PATTERN 的目录将被跳过。
+ -L, --files-without-match 仅打印不包含匹配项的文件名
+ -l, --files-with-matches 只打印包含匹配项的文件名
+ -c, --count 仅打印每个文件的匹配行数
+ -T, --initial-tab 使标签对齐(如果需要)
+ -Z, --null 在文件名后打印 0 字节
+
+上下文控制:
+ -B, --before-context=NUM 打印前导上下文的 NUM 行
+ -A, --after-context=NUM 打印 NUM 行尾随上下文
+ -C, --context=NUM 打印 NUM 行输出上下文
+ -NUM 与 --context=NUM 相同
+ --group-separator=SEP 使用 SEP 作为组分隔符
+ --no-group-separator 使用空字符串作为组分隔符
+ --color[=WHEN],
+ --color[=WHEN] 使用标记突出匹配的字符串;
+ WHEN 是“总是”、“从不”或“自动”
+ -U, --binary 在 EOL (MSDOS/Windows) 时不去除 CR 字符
+ -u, --unix-byte-offsets 报告偏移量,就好像 CR 不存在一样
+ (MSDOS/Windows)
+
+“egrep”的意思是“grep -E”。 “fgrep”的意思是“grep -F”。
+不推荐直接调用“egrep”或“fgrep”。
+当 FILE 为 - 时,读取标准输入。没有 FILE,阅读 .如果是命令行
+-r 给出, - 否则。如果给出的 FILE 少于两个,则假定为 -h。
+如果选择了任何一行,则退出状态为 0,否则为 1;
+如果发生任何错误且未给出 -q,则退出状态为 2。
+
+将错误报告至:bug-grep@gnu.org
+GNU Grep 主页:
+使用 GNU 软件的一般帮助:
+```
+
+
+
+
+
+
+> linux通过grep根据关键字查找日志文件上下文 https://www.cnblogs.com/xuzhujack/p/11116525.html
+
diff --git a/linux/linux使用sed命令.md b/linux/linux使用sed命令.md
new file mode 100644
index 0000000..64e0e06
--- /dev/null
+++ b/linux/linux使用sed命令.md
@@ -0,0 +1 @@
+# linux使用sed命令
\ No newline at end of file
diff --git a/linux/linux免密登录.md b/linux/linux免密登录.md
new file mode 100644
index 0000000..5ce50c2
--- /dev/null
+++ b/linux/linux免密登录.md
@@ -0,0 +1,105 @@
+# linux 免密登录
+
+
+
+为了保证一台Linux主机的安全,每个主机登录的时候都需要账号密码。但是很多时候为了操作方便,需要设置集群互信主机之间的SSH免密码登录。
+
+## 一、公钥与私钥
+
+大家可能都知道密钥的概念,在传统的加密算法中,加密和解密使用的是同一个密钥,一旦该密钥泄露,那么加密内容将被破解。通常在现代密码体系中加密和解密是采用不同的密钥,也就是大家经常听说到的**非对称加密**。
+
+**非对称加密算法的公钥私钥的原则:**
+
+1. 一个公钥对应一个私钥,二者是成对出现的。
+2. 公钥私钥密钥对需要有一个发布方,发布方自己保存的密钥通常被称为私钥,公开发布给其他方使用的密钥被称为公钥。
+3. 公钥加密结果,对应的私钥能解;私钥加密结果,对应的的公钥能解。
+
+## 二、ssh免密登录原理
+
+
+
+- 如果host1希望免密登录host2,那么密钥对是host1发布的。
+- 让host2信任host1的公钥,host1即可免密登录host2。所以host1需要将自己的公钥,在host2服务器上保存一份(复制密钥)
+
+## 三、密钥文件
+
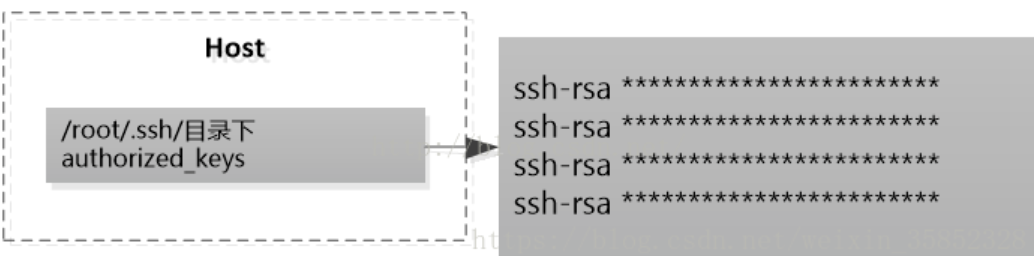
+在被SSH登录的主机中,都有一个存储来登录的主机的公钥的文件,它的名字叫做authorized_keys,它的位置就在`/<登录用户根目录>/.ssh`目录中(注:如果这台主机没有被设置任何免秘钥登录,这个文件缺省是不存在的)
+
+
+
+在authorized_keys文件中,存储着能够登录本地主机的其他各个主机的身份信息。如果使用rsa算法生成的密钥,文件的存储格式都是以ssh-rsa开头的一组字符串。
+
+## 四、密码生成与密钥分发(免密登录)
+
+### 4.1.环境准备
+
+主机环境
+
+| ip | 主机名称 | 规划用户 |
+| :------------ | :------- | :------- |
+| 192.168.1.111 | zimug1 | kafka |
+| 192.168.1.112 | zimug2 | kafka |
+| 192.168.1.113 | zimug3 | kafka |
+
+### 4.2.生成密钥对
+
+因为我们后续为了搭建kafka集群,并且使用的kafka用户,所以生成密钥对之前用kafka用户登录主机。首先在zimug1主机执行下面的命令。
+
+```
+ssh-keygen -t rsa
+```
+
+出现提示输入信息,一路回车即可。
+
+执行完成之后,我们会在`/home/kafka/.ssh`目录下看到下面的这两个文件。通常认为前者是公钥,后者是私钥。
+
+```
+id_rsa.pub
+id_rsa
+```
+
+### 4.3.密钥处理
+
+- 将公钥保存到authorized_keys文件中
+
+```sh
+cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
+```
+
+- 将公钥分发给zimug2、zimug3主机。按提示输入kafka登陆密码
+
+```sh
+ssh-copy-id -i ~/.ssh/id_rsa.pub -p22 kafka@zimug2;
+```
+
+需要分开执行,因为需要输入密码。
+
+```sh
+ssh-copy-id -i ~/.ssh/id_rsa.pub -p22 kafka@zimug3;
+```
+
+这样,我们zimug1免密登录zimug2、zimug3的配置工作就完成了。
+
+### 4.4.免密登录测试
+
+在zimug1主机上登录zimug2(或zimug3)主机,输入如下命令,不需要输入密码。你会发现登录主机的切换如下,不需要密码就完成登陆了。
+
+```
+[kafka@zimug1 ~]$ ssh kafka@zimug2
+Last login: Sat Feb 19 22:07:13 2022 from 192.168.137.10
+[kafka@zimug2 ~]$
+```
+
+如果想退回到zimug1服务器,使用`exit`命令。
+
+如果此时你执行免密登陆测试失败,请执行这三个命令修改主目录及文件权限。如果还不行,重新执行上面的步骤。
+
+```
+chmod 755 ~/;
+chmod 700 ~/.ssh/;
+chmod 600 ~/.ssh/authorized_keys;
+```
+
+### 4.5 重复
+
+在zimug2、zimug3服务器上重复以上步骤,就可以完全实现三台服务器之间ssh免密登录互通互联。
\ No newline at end of file